AI霸权是否面临终结?深度解析中美开源战略的产业博弈
回顾科技发展的历史长河,从互联网基础设施的构建到移动互联网的爆发,每一次技术范式的转移都伴随着权力版图的重构。近日,美国国会咨询机构美中经济与安全审查委员会发布的一份报告,将全球目光聚焦于人工智能领域的开源生态竞争。报告披露了一个令业界瞩目的数据:超过80%的美国AI初创企业正在使用中国开源模型,这一现象引发了关于美国AI领先地位是否稳固的广泛讨论。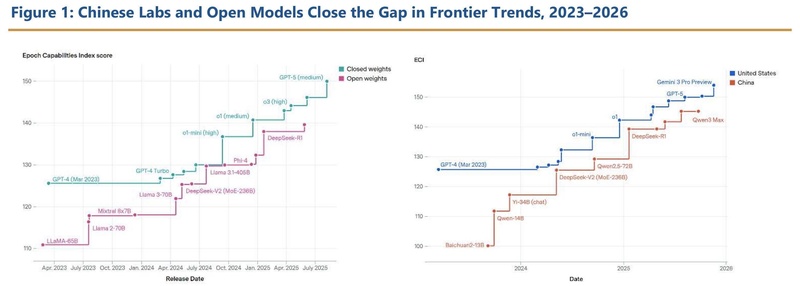
时间回溯至2001年,该委员会的设立初衷是监测中美贸易对美国经济的影响。然而,在当前的AI竞争语境下,该机构的关注点已转向中国依托制造业优势形成的双循环反馈机制。这种机制并非单纯的算法堆砌,而是将数字创新与实体产业深度绑定。根据报告分析,即便在高端芯片供应受限的背景下,中国科研机构通过开源生态,实现了模型性能的快速迭代,在核心架构与训练方法上取得了实质性突破。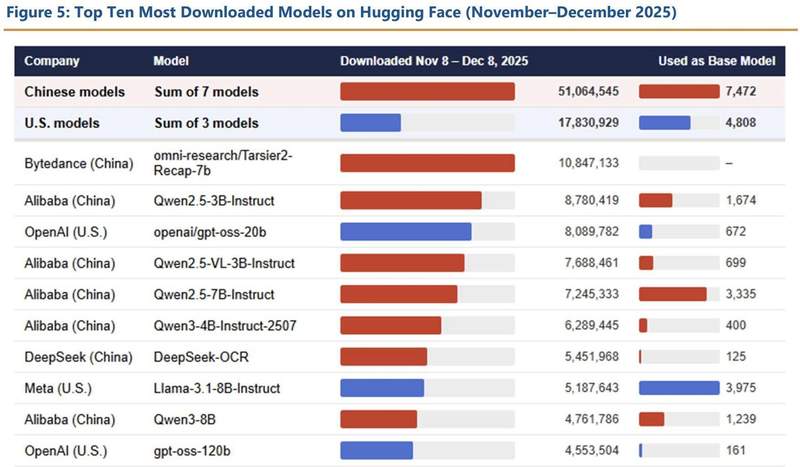
数据支撑了这一判断,HuggingFace平台的数据显示,DeepSeek推出的R1模型迅速在AppStore获得高下载量,阿里巴巴的千问系列模型在全球范围内的下载表现同样强劲。这种趋势表明,中国AI的发展路径已从单纯的算力堆砌转向了场景化落地,通过在机器人、工业自动化等领域的海量实景数据积累,完成了模型的反向优化。这种环环相扣的创新飞轮,使得美国依赖算力限制的传统围堵策略面临失效风险。
工业场景数据成为核心资产
工业数据不仅是生产流程的记录,更是AI模型进化的核心燃料。随着制造流程的数字化升级,海量的生产参数、设备运行日志以及物流路径数据被实时采集,这些独有的实景数据为中国模型提供了闭源模型难以获取的训练素材。
这种数据优势直接转化为模型的应用效能。在具身智能与人形机器人领域,实景数据的介入使得模型能够更精准地理解物理世界的复杂性,从而在复杂工业场景中实现低成本部署,这种落地效率是目前美国依赖纯数据中心训练的闭源模型所缺乏的。
未来,行业标准制定权的争夺将不仅取决于参数量级,更取决于谁能率先将AI深度嵌入实体产业链,通过规模化应用沉淀出具有统治力的行业规范,这正是当前中国开源AI战略带来的长期挑战。



